 AI insights
AI insights About us
About us Careers
Careers Security
Security Customer reviews
Customer reviews Contact us
Contact us Affiliate program
Affiliate program Solution partners
Solution partners Looker Studio templates
Looker Studio templates Tableau templates
Tableau templates Facebook Ads templates
Facebook Ads templates Google Ads templates
Google Ads templates Data fields & Metrics
Data fields & Metrics AI prompt library & Guides
AI prompt library & Guides Product documentation
Product documentation API documentation
API documentation Case studies
Case studies Blog
Blog Data models
Data models Windsor vs Supermetrics
Windsor vs Supermetrics Windsor vs Fivetran
Windsor vs Fivetran Windsor vs Portermetrics
Windsor vs Portermetrics Last updated: 21 May 2025
Last updated: 21 May 2025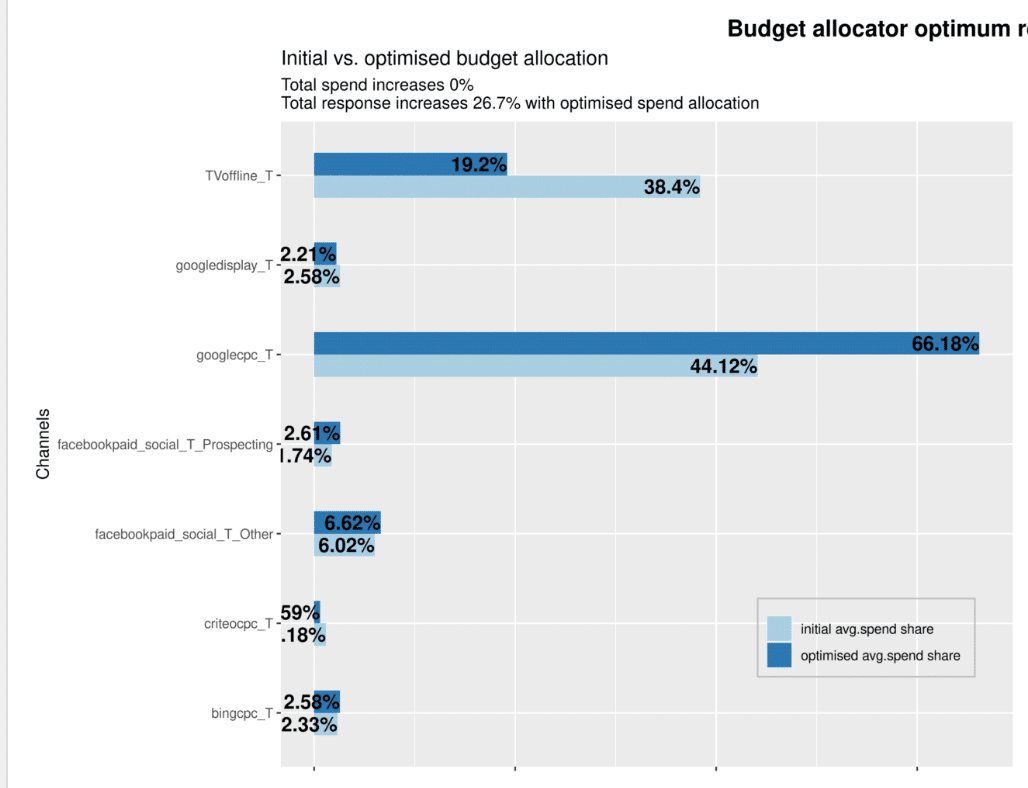

Example of Marketing mix modeling with Facebook’s Robyn package
Here I will go through an example of how to run marketing mix modeling with the Robyn package published by Facebook. The project page by Facebook is here: https://facebookexperimental.github.io/Robyn/ and here are the instructions and code: https://github.com/facebookexperimental/Robyn
Ever since Facebook published the package many have asked us how they can run it in addition to the attribution modelling and automated marketing mix modeling we provide.
We improved Facebook’s code a little bit so that its easier to get all the data together and run it. The package requires data in a long format so we also created a script to prepare the data.
Steps to run marketin mix modeling with Robyn:
- Connect your datasources in https://onboard.windsor.ai
We recommend connecting all your important marketing channels like Google Ads, Facebook Ads but also it is good to connect one analytics channels like Google Analytics that can be used to get the absolute value of revenue or conversions. - On the destinations tab in onboard.windsor.ai create a ROAS or CPA dashboard so that the data gets loaded.
- Clone the repository with the Robyn improvements with the command:
git clone [email protected]:nkolster/Robyn-improvements.git
TODO improve once it works for connectors - Create an configuration file for the user containing the sourcemediums you would like to use.
- Prepare the data for Robyn with the command:
python3 robyn_data_preparation.py --json-url "http://charts.windsor.ai/r/6955?api_key=<APIKEY>" --user <username> - Run the modelling with the command:
Rscript robyn_exec.R --user decathlon --set_trial 100 --set_iter 700 --alphas 0.1,5 --gammas 0.01,1 --thetas 0.01,0.7
You can of course adjust the parameters as you need.
The script will output first the models into png files.
There it will show both the proportion of spend and the impact of that spend.
Then it also shows the curves with the dimishing returns and how well the model has been fitted.
It will then select the best model and optimise the budgets based on that.
It will also output the png files for this where the optimised budgets can be seen.

We recommend to compare these results with our multitouch attribution model results and also the budget optimiser results.
Also when budget shifts are made its good to make them gradually and monitor the impact. Then if the impact is as expected to continue in the same direction.
Market mix modelling is a good way to double-check the impact of channels where eg. measuring the impressions can be impossible.
The full code of the R script is here below.
We improved it so the ranges for the hyperparameters can be given as an argument and it takes all variables from the configuration file so its easier to run.
usePackage <- function(p) {
if (!is.element(p, installed.packages()[,1])) {
print(paste(‘INSTALLING PACKAGE:’, p))
# the next line could fail on the local machine without repo names
#
# install.packages(p, dep = TRUE, repos=”http://cran.us.r-project.org”)
#
install.packages(p, dep = TRUE)
}
suppressMessages(require(p, character.only = TRUE, quietly = TRUE))
}
usePackage(“corrplot”)
usePackage(“glmnet”)
usePackage(“reticulate”)
usePackage(“data.table”)
usePackage(“stringr”)
usePackage(“lubridate”)
usePackage(“doParallel”)
usePackage(“foreach”)
usePackage(“glmnet”)
usePackage(“car”)
usePackage(“StanHeaders”)
# usePackage(“prophet”)
# usePackage(“rstan”)
usePackage(“ggplot2”)
usePackage(“gridExtra”)
usePackage(“grid”)
usePackage(“ggpubr”)
usePackage(“see”)
usePackage(“PerformanceAnalytics”)
usePackage(“nloptr”)
usePackage(“minpack.lm”)
usePackage(“rPref”)
usePackage(“reticulate”)
usePackage(“rstudioapi”)
usePackage(“data.table”)
usePackage(“doFuture”)
usePackage(“doRNG”)
usePackage(“RPostgres”)
usePackage(“DBI”)
usePackage(“dplyr”)
usePackage(“optparse”)
usePackage(“here”)
# conda_create(“r-reticulate”) #must run this line once only
conda_install(“r-reticulate”, “nevergrad”, pip=TRUE) #must install nevergrad in conda before running Robyn
use_condaenv(“r-reticulate”)
ng <- import(“nevergrad”)
script_path <- paste(here(), “/Robyn_model/”, sep = “”)
# Uncomment it if it is running in R studio
# script_path <- str_sub(rstudioapi::getActiveDocumentContext()$path, start = 1, end = max(unlist(str_locate_all(rstudioapi::getActiveDocumentContext()$path, “/”))))
source(paste(script_path, “Robyn-master/source/fb_robyn.func.R”, sep=””))
source(paste(script_path, “Robyn-master/source/fb_robyn.optm.R”, sep=””))
source(paste(script_path, “helpers.R”, sep=””))
# Create a parser
parser <- get_parser()
# Parse arguments
tryCatch({
parsed_args <- parse_args(parser)
}, error = function(e){
parsing_error <- grepl(‘Error in getopt\\(spec = spec, opt = args\\) :’,
e$message)
if(isTRUE(parsing_error)) {
cat(‘Error: Incorrect option\n’)
print_help(parser)
stop(call. = FALSE)
} else {
print(e$message)
}
})
client_name <- parsed_args[[‘user’]]
# parsed_args[[‘user’]] = “bettzeit”
# Check whether client name is defined
if(is.null(parsed_args[[‘user’]])) {
cat(‘Error: Client name is required but not supplied\n’)
print_help(parser)
stop(call. = FALSE)
}
# Read config file with general settings
path_to_config <- paste0(script_path,’config.yml’)
# Check if config file exists
if(isFALSE(path_to_config)) {
cat(‘Error: There is no config file.\n’)
print_help(parser)
stop(call. = FALSE)
}
# Check if plots folder exists
path_to_plots <- paste0(script_path,client_name,”/plots”)
if(isFALSE(file.exists(path_to_plots))) {
cat(‘Creating a “plots” folder.\n’)
dir.create(path_to_plots )
}
config <- yaml::yaml.load_file(path_to_config)
config$database_name <- gsub(“CLIENT_NAME”, client_name, config$database_name)
# Read config file with custom settings
path_to_config <- paste0(script_path,client_name,’/config.yml’)
# Check if config file exists
if(isFALSE(path_to_config)) {
cat(‘Error: There is no config file.\n’)
print_help(parser)
stop(call. = FALSE)
}
custom_config <- yaml::yaml.load_file(path_to_config)
# Read training dataset
path_to_train_df <- paste0(script_path,client_name,’/train_dataset_for_robyn.csv’)
# Check if training dataset exists
if(isFALSE(file.exists(path_to_train_df ))) {
cat(‘Error: There is no train dataset. Run robyn_data_preparation.py to load train dataset.\n’)
print_help(parser)
stop(call. = FALSE)
}
dt_input <- fread(path_to_train_df ) # input time series should be daily, weekly or monthly
# dt_holidays <- fread(paste0(script_path,’Robyn-master/source/holidays.csv’)) # when using own holidays, please keep the header c(“ds”, “holiday”, “country”, “year”)
#Correlation plot
num_dt_input <- dt_input %>% dplyr::select(where(is.numeric))
num_dt_input <- num_dt_input %>% select_if(colSums(.) != 0)
dt_corr <- cor(num_dt_input)
col <- colorRampPalette(c(“#BB4444”, “#EE9988”, “#FFFFFF”, “#77AADD”, “#4477AA”))
corrplot(dt_corr, method=”color”, col=col(100),
type=”upper”, order=”hclust”,
addCoef.col = “black”, # Add coefficient of correlation
tl.col=”black”, tl.srt=35, tl.cex = 0.55,tl.offset = 1.5,#Text label color and rotation
number.cex=0.75,
# Combine with significance
# p.mat = p.mat, sig.level = 0.1, insig = “blank”,
# hide correlation coefficient on the principal diagonal
diag=FALSE
)
set_modTrainSize <- 0.74
set_dateVarName <- c(custom_config$colnames$date_col) # date must be format “2020-01-01”
set_depVarName <- c(“total_revenue”) # there should be only one dependent variable
set_depVarType <- “revenue” # “revenue” or “conversion” are allowed
# Add impression col if it exists
# Fields that cinatin “I” it is impressions and “S” it is totalspend
if (“impressions_col” %in% names(custom_config$colnames)){
impressions_cols <- grep(‘_I’, colnames(dt_input), value=TRUE)
} else {impressions_cols <- c()}
set_mediaVarName <- sort(setdiff(grep(‘_I|_S’, colnames(dt_input), value=TRUE), gsub(“_I”,”_S”,impressions_cols)))
set_mediaSpendName <- sort(grep(‘_S’, colnames(dt_input), value=TRUE))
set_mediaVarSign <- rep(“positive”, length(set_mediaVarName))
activate_prophet <- F # Turn on or off the Prophet feature
# set_prophet <- c(“trend”, “season”, “holiday”) # “trend”,”season”, “weekday”, “holiday” are provided and case-sensitive. Recommended to at least keep Trend & Holidays
# set_prophetVarSign <- c(“default”,”default”, “default”) # c(“default”, “positive”, and “negative”). Recommend as default. Must be same length as set_prophet
activate_baseline <- F
# set_baseVarName <- c(“competitor_sales_B”) # typically competitors, price & promotion, temperature, unemployment rate etc
# set_baseVarSign <- c(“negative”) # c(“default”, “positive”, and “negative”), control the signs of coefficients for baseline variables
set_factorVarName <- c()
## set cores for parallel computing
registerDoSEQ(); detectCores()
set_cores <- 6 # I am using 6 cores from 8 on my local machine. Use detectCores() to find out cores
## set rolling window start (only works for whole dataset for now)
set_trainStartDate <- unlist(dt_input[, lapply(.SD, function(x) as.character(min(x))), .SDcols= set_dateVarName])
set_trainStartDate <- min(dt_input[[set_dateVarName]])
## set model core features
adstock <- “geometric” # geometric or weibull. weibull is more flexible, yet has one more parameter and thus takes longer
set_iter <- parsed_args$set_iter # number of allowed iterations per trial. 500 is recommended
set_hyperOptimAlgo <- “DiscreteOnePlusOne” # selected algorithm for Nevergrad, the gradient-free optimisation usePackage https://facebookresearch.github.io/nevergrad/index.html
set_trial <- parsed_args$set_trial # number of allowed iterations per trial. 40 is recommended without calibration, 100 with calibration.
## Time estimation: with geometric adstock, 500 iterations * 40 trials and 6 cores, it takes less than 1 hour. Weibull takes at least twice as much time.
## helper plots: set plot to TRUE for transformation examples
f.plotAdstockCurves(T) # adstock transformation example plot, helping you understand geometric/theta and weibull/shape/scale transformation
f.plotResponseCurves(T) # s-curve transformation example plot, helping you understand hill/alpha/gamma transformation
################################################################
#### tune channel hyperparameters bounds
#### Guidance to set hypereparameter bounds ####
## 1. get correct hyperparameter names:
local_name <- f.getHyperNames(); local_name # names in set_hyperBoundLocal must equal names in local_name, case sensitive
## 3. set each hyperparameter bounds. They either contains two values e.g. c(0, 0.5), or only one value (in which case you’ve “fixed” that hyperparameter)
set_hyperBoundLocal <- list()
# Convert hyperparameter bounds to numeric format
parsed_args$alphas <- as.numeric(unlist(strsplit(as.character(parsed_args$alphas),”,”)))
parsed_args$gammas <- as.numeric(unlist(strsplit(as.character(parsed_args$gammas),”,”)))
parsed_args$thetas <- as.numeric(unlist(strsplit(as.character(parsed_args$thetas),”,”)))
for (col in set_mediaVarName ){
set_hyperBoundLocal[[paste(col,”alphas”, sep = “_”)]] <- c(parsed_args$alphas[1], parsed_args$alphas[2])
set_hyperBoundLocal[[paste(col,”gammas”, sep = “_”)]] <- c(parsed_args$gammas[1], parsed_args$gammas[2])
set_hyperBoundLocal[[paste(col,”thetas”, sep = “_”)]] <- c(parsed_args$thetas[1], parsed_args$thetas[2])
}
activate_calibration <- F # Switch to TRUE to calibrate mode
################################################################
#### Prepare input data
dt_mod <- f.inputWrangling()
################################################################
#### Run models
model_output_collect <- f.robyn(set_hyperBoundLocal
,optimizer_name = set_hyperOptimAlgo
,set_trial = set_trial
,set_cores = set_cores
,plot_folder = path_to_plots) # please set your folder path to save plots. It ends without “/”.
# reload old models from csv
# dt_hyppar_fixed <- fread(“/Users/gufengzhou/Documents/GitHub/plots/2021-04-07 09.12/pareto_hyperparameters.csv”) # load hyperparameter csv. Provide your own path.
# model_output_collect <- f.robyn.fixed(plot_folder = “~/Documents/GitHub/plots”, dt_hyppar_fixed = dt_hyppar_fixed[solID == “2_16_5”]) # solID must be included in the csv
################################################################
#### Budget Allocator – Beta
#Select best model
nrmse_min = min(model_output_collect$resultHypParam$nrmse)
cat(“Min NRMSE: “, nrmse_min)
if (nrmse_min <= as.numeric(config$nrmse_threshold)){
best_modID = model_output_collect$resultHypParam[model_output_collect$resultHypParam$nrmse == nrmse_min, ]$solID
cat(“Best nodel: “, best_modID)
} else {stop(“There’s no satisfying Robyn MMM result”)}
## Budget allocator result requires further validation. Please use this result with caution.
## Please don’t interpret budget allocation result if there’s no satisfying MMM result
model_output_collect$allSolutions
optim_result <- f.budgetAllocator(modID = best_modID # input one of the model IDs in model_output_collect$allSolutions to get optimisation result
,scenario = “max_historical_response” # c(max_historical_response, max_response_expected_spend)
#,expected_spend = 100000 # specify future spend volume. only applies when scenario = “max_response_expected_spend”
,expected_spend_days = 90 # specify period for the future spend volumne in days. only applies when scenario = “max_response_expected_spend”
,channel_constr_low = rep(0.5,length(set_mediaVarName)) # must be between 0.01-1 and has same length and order as set_mediaVarName
,channel_constr_up = rep(1.5,length(set_mediaVarName)) # not recommended to ‘exaggerate’ upper bounds. 1.5 means channel budget can increase to 150% of current level
)
For all the code it can be easiest to get it from here: https://github.com/nkolster/Robyn-improvements

