 AI insights
AI insights About us
About us Careers
Careers Security
Security Customer reviews
Customer reviews Contact us
Contact us Affiliate program
Affiliate program Solution partners
Solution partners Looker Studio templates
Looker Studio templates Tableau templates
Tableau templates Facebook Ads templates
Facebook Ads templates Google Ads templates
Google Ads templates Data fields & Metrics
Data fields & Metrics AI prompt library & Guides
AI prompt library & Guides Product documentation
Product documentation API documentation
API documentation Case studies
Case studies Blog
Blog Data models
Data models Windsor vs Supermetrics
Windsor vs Supermetrics Windsor vs Fivetran
Windsor vs Fivetran Windsor vs Portermetrics
Windsor vs Portermetrics Last updated: 16 February 2026
Last updated: 16 February 2026

These days, companies generate over 328 million terabytes of data daily. That’s a massive amount — and managing, shaping, and making value of that data is essential if you want accurate reports, always up-to-date insights, and effective data-driven decisions. That’s where ELT (Extract, Load, Transform) pipelines come in.
ELT is a data integration method where raw data is pulled from source systems, loaded directly into a destination (such as a BI tool, data warehouse, or data lake), and then cleaned or transformed after loading.
The ELT process is typically faster, more scalable, and better suited to handling large and complex datasets than traditional manual data uploads.
In this post, we’ll break down what ELT data pipelines are, how they work, and why they’re essential if you’re dealing with big, messy data from multiple platforms. We’ll also compare ELT with ETL, walk through typical ELT setup steps, cover common challenges and solutions, and explore real-world examples — including how modern ELT tools like Windsor.ai automate data flows between source platforms and destinations.
Understanding the ELT concept
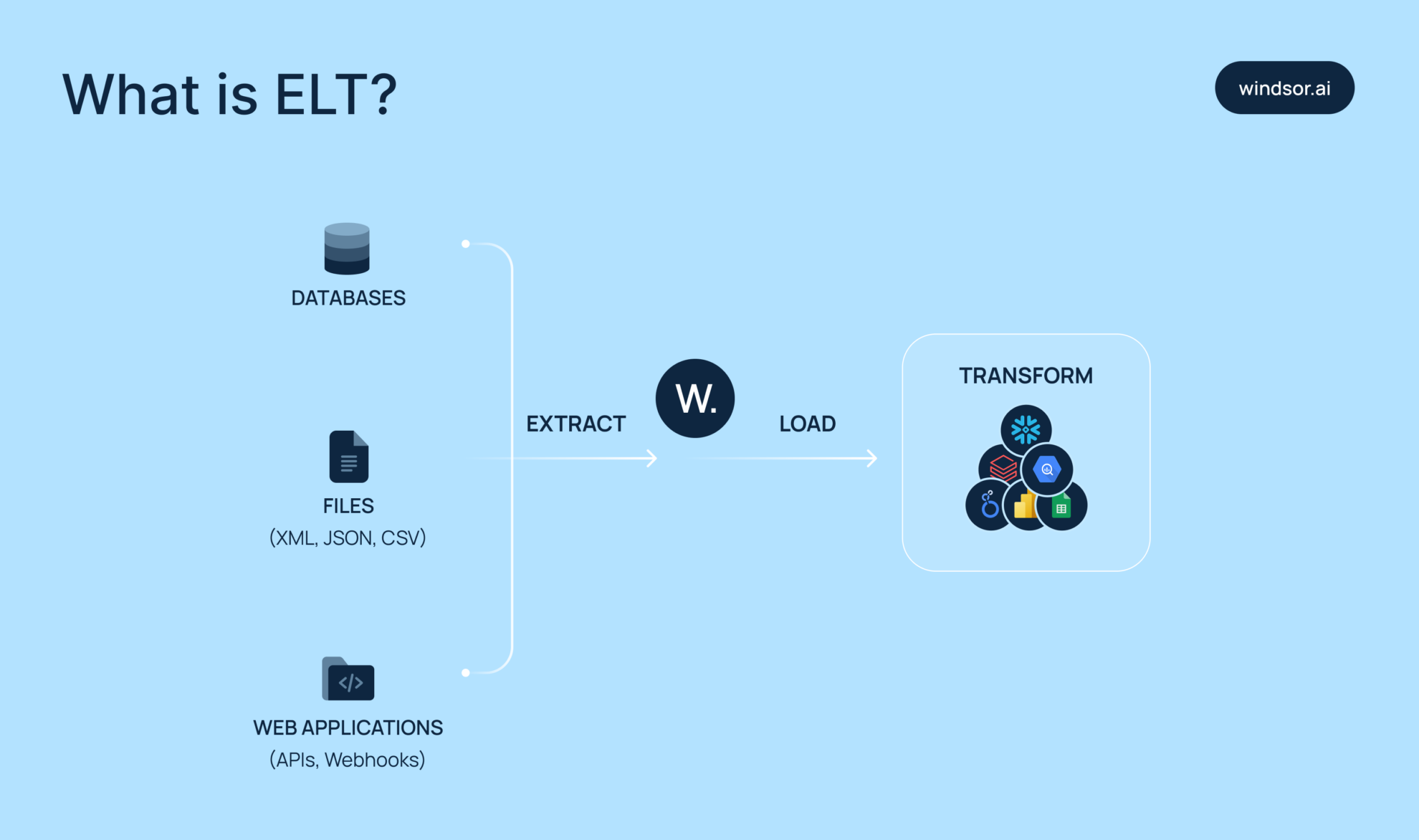
What is ELT?
ELT stands for Extract, Load, and Transform — it’s a modern approach to moving data from source systems like apps or databases into analytics or storage environments such as cloud data warehouses, data lakes, or BI platforms.
The key advantage of ELT is flexibility. Since the raw data stays untouched in the storage layer, you can build and adjust multiple transformation workflows without re-extracting or risking source data integrity. This is ideal for use cases like reporting, dashboarding, machine learning, or experimentation.
Because the heavy lifting happens in the cloud (where compute resources scale), ELT pipelines tend to be faster and more scalable, especially for large or complex datasets. Compared to the traditional ETL approach, ELT is typically quicker to implement, easier to maintain, and better suited to modern data stacks.
How does ELT work?
As the name suggests, ELT works as follows:
- Extract: You start by pulling raw data from your source — that might be a SaaS app, web analytics platform, CRM, ERP, or any system with an accessible API. Extraction methods are adaptable, whether via batch loads, real-time streams, or API calls, depending on the specifics and capabilities of the data source.
- Load: Next, you load the extracted data directly into your destination system — typically a centralized storage layer like BigQuery, Snowflake, Redshift, spreadsheets, or data visualization platforms like Looker Studio, Power BI, Tableau, etc. At this point, you’re not transforming the data yet — just loading it in as-is. This “dump-first” approach makes it easier to unify everything in one place before you start making changes.
- Transform: Finally, you clean, shape, and enrich the data inside the destination. You might filter out unnecessary rows, join tables, normalize fields, reformat values, or apply business logic — all using the compute power and transformation tools native to your destination platform.
ELT vs. ETL: key differences
With ELT, you extract data from different places and stream it right into your destination system, usually some kind of data warehouse or BI tool. After it lands, you run your transformations there, like reformatting, filtering, or running calculations. It’s ideal if your team needs to extract and preview data quickly, then handle cleanup and structuring later.
ETL flips that order. You extract the data, transform it right away (e.g., by cleaning, filtering, or reformatting), and then load the processed data into the destination. This is particularly useful when working with very messy data that needs to be standardized before storage, especially in systems that demand high performance and consistency (like MPP data warehouses).
The core difference between ELT and ETL is when you transform the data:
- ETL transforms data before loading
- ELT transforms data after loading
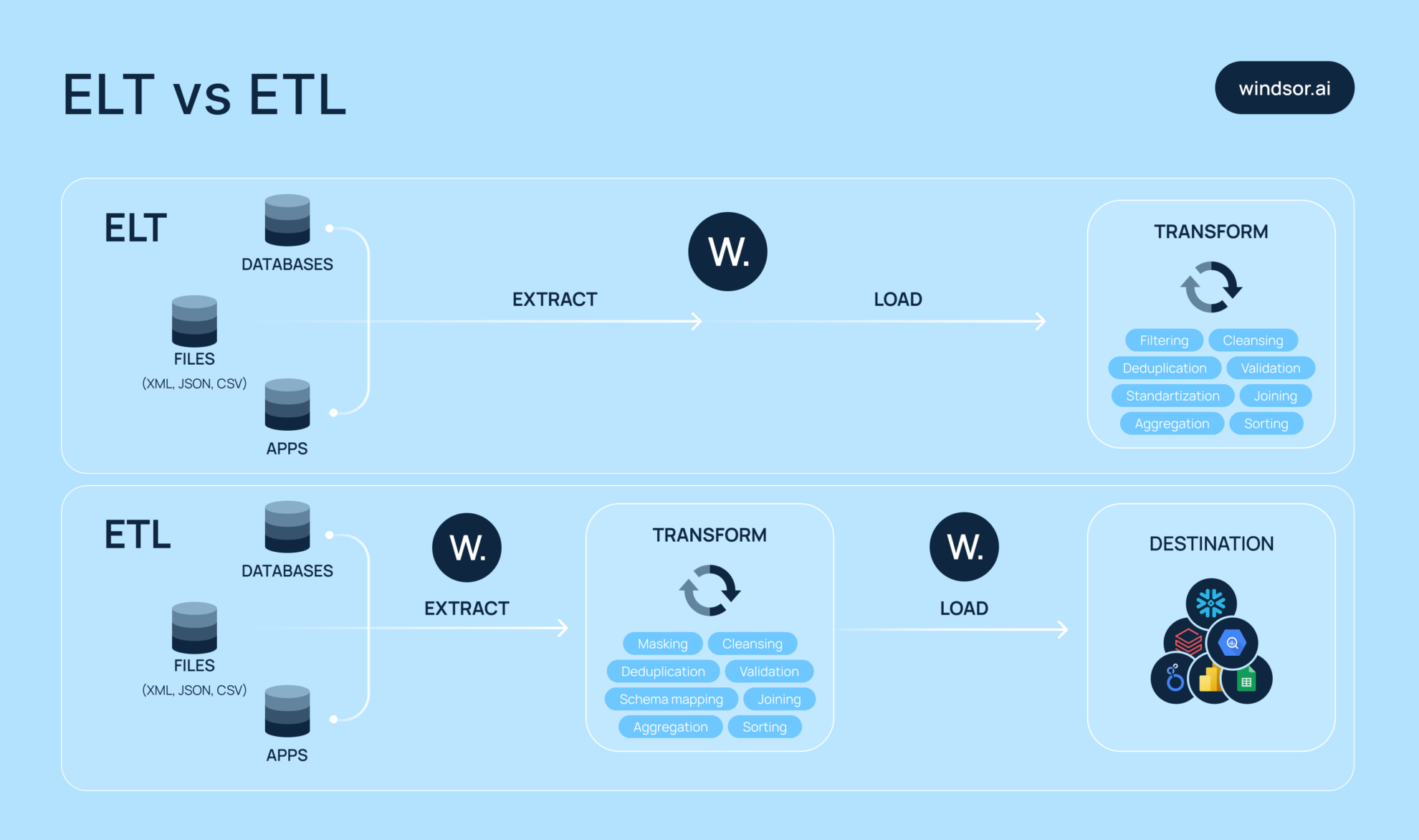
Important to note that ETL gives you clean, ready-to-use data up front, but it can slow down as data grows. ELT skips that bottleneck by offloading the transformation workload to powerful cloud-based systems.
Here is a quick summary of ETL vs ELT:
| Aspect | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
| Process order | Clean first, then load | Load first, clear later |
| Best for | When data is messy and must be cleaned upfront | When speed matters or minimal transformation is needed |
| Target system | Traditional data warehouses | Modern cloud data platforms |
| Transformation | Happens before loading | Happens after loading, inside the destination |
| Performance | Can slow down with large datasets | Handles large data loads efficiently |
| Flexibility | Less flexible; requires fixed logic upfront | More flexible; raw data is preserved and reusable |
| Tools & tech | Legacy tools like Talend, Informatica | Modern tools like Windsor.ai |
| Output | Cleaned, ready-to-use data | Raw data, transformations applied as needed |
Use cases for ELT pipelines in business
ELT pipelines start to make a lot more sense once you see how they’re used in real business cases — and their applications are nearly endless.
Let’s start with real-time analytics. ELT pipelines let you stream raw event data directly into your cloud warehouse. Once it’s there, you can clean and transform it on demand. Since data in the destination is continuously updated, it’s ideal for powering live dashboards or tracking KPIs without delays.
Now think about data storage and advanced analytics. Businesses today are ingesting huge volumes of unstructured data into cloud data lakes and warehouses like BigQuery, Snowflake, and Redshift. With ELT, you can dump massive datasets into one centralized location within minutes — no manual uploads needed — making the data immediately available for exploration, modeling, or long-term storage. Many companies use ELT pipelines to prepare training data for machine learning models and predictive analytics.
For marketing teams, ELT is a game-changer. It enables them to pull hundreds of metrics from CRMs, ad platforms, web analytics tools, and more, then consolidate everything into a single location for unified, cross-channel reporting and campaign analysis.
Finance teams love ELT, too. They often work with transactional data from multiple systems. ELT helps ingest raw financial data quickly and enables teams to run calculations, reconciliations, and aggregations directly in the data warehouse.
And for data scientists, ELT offers a flexible playground. They get access to raw, untouched data, allowing them to experiment freely, without risking production systems or spending time wrangling APIs.
ELT makes modern data management faster, more adaptable, and far more efficient. It supports agile workflows across departments, enabling better collaboration and quicker insights across your organization.
What is an ELT data pipeline architecture?
Let’s break down the ELT data pipeline architecture in simple terms.
It starts with collecting data from external sources using data connectors like Windsor.ai. These connectors pull data from your tools, databases, cloud apps — you name it. You can schedule how often the data is extracted, whether every hour, once a day, or at custom intervals.
The raw data is then loaded directly into a storage layer, usually a cloud data warehouse like Snowflake, Redshift, or BigQuery. At this point, it’s untouched — exactly as it came from the source.
Next comes the transformation phase. This happens inside the destination system. You use SQL or tools like dbt to join tables, filter noise, standardize formats, and apply business logic. Because the transformations run where the data already lives, the whole process is efficient and scalable.
You can also build views or data marts — clean, curated tables optimized for dashboards, reports, or machine learning models. Each team gets exactly what they need, without altering or accessing the raw data directly.
To make things even smoother, you can integrate orchestration tools to automate tasks, manage dependencies, and receive alerts if anything breaks in your pipeline.
The beauty of ELT architecture is its modularity. You can easily add new data sources, adjust logic, or scale up without friction. ELT grows with your business — no stress, no bottlenecks.
Advantages of ELT pipelines for businesses
Faster data ingestion
With ELT, you stream raw data directly into your destination — no manual steps or preprocessing required. There’s no need to clean it first, which means your team can start analyzing and extracting insights much faster.
It’s especially helpful when you need to act quickly — like making a fast decision based on the latest available data.
Better scalability
Cloud data platforms are built to handle crazy amounts of data. Since transformations happen directly inside these systems, performance stays smooth even as your data grows. No slowdowns, no bottlenecks.
More flexibility
Because the raw data remains untouched in storage, you’re not locked into a single transformation logic. Want to tweak a report, run a new ML model, or explore a different analysis? Just spin up a new view — no need to rewrite or reload data.
Easier maintenance
Business needs change all the time — new metrics, logic updates, shifting priorities. ELT pipelines are easy to maintain: just update a SQL script or modify a dbt model. No need to tear everything down or rebuild from scratch.
Support for diverse data
Whether it’s JSON, logs, clickstream events, or oddly formatted exports, ELT handles all kinds of raw data with ease.
You can dump it all in first and clean it up later, making it much easier to manage messy or unconventional data sources over time.
Common challenges and limitations of using ELT pipelines
Resource-heavy transformations
Running complex transformations inside your data warehouse can consume a lot of compute power. Heavy joins and long SQL queries increase processing time — and your bill. Without proper monitoring, costs can spike unexpectedly.
Data quality issues
Loading raw data directly into the warehouse means you’re bringing in all the noise — bad values, duplicates, missing fields, broken formats. If you don’t validate or clean early enough, your dashboards and reports could be built on unreliable data. Setting up data quality checks and alerts is critical from the start.
Storage costs
Raw data takes up space fast. Keeping large volumes over time, especially without cleanup, can lead to rising storage costs. Use partitioning, retention policies, and data archiving strategies to stay in control.
Complex orchestration
ELT still needs solid orchestration. You’ll have to manage job schedules, task dependencies, and error handling across the entire pipeline. If one step fails, downstream reports might break or go stale.
Limited real-time capability
ELT works best with batch processing. While near real-time is possible, it’s more complex and often more expensive. If you need live updates, consider using third-party ELT tools that support near real-time sync.
Skill and maintenance requirements
ELT pipelines require expertise, including SQL skills, data modeling knowledge, and familiarity with orchestration tools. As your pipelines evolve, your team must actively monitor, test, and update workflows to keep everything running smoothly.
How automated ELT tools solve these challenges
What is an ELT tool?
While ELT pipelines come with a set of challenges, third-party ELT tools like Windsor.ai eliminate these barriers by automating data integration.
Here’s how they work: first, the tool connects to your data sources—whether databases, marketing APIs, or SaaS platforms—and loads all raw data directly into your data warehouse or BI tool without modification (some ELT tools provide preliminary data transformations).
Next, you define how to transform and clean that data inside the warehouse itself, leveraging its processing power for faster and more efficient data preparation. Many ELT tools also include features like automated scheduling and alerts to notify you if anything in your ELT pipeline goes wrong.
The result? You save significant time and reduce manual work, enabling faster, more reliable access to clean, actionable data.
Windsor.ai: leading ELT tool for marketing and data teams
Windsor.ai takes a step forward in the ELT sector and handles data extraction, loading, and even basic transformations — such as format standardization and automatic schema matching — with no need for manual pipeline monitoring or custom code. It supports scheduled data refreshes, integrates with 325+ external platforms, and includes built-in data validation to catch quality issues early.
Thanks to its resource-efficient features like support for partitioning and clustering, and flexible pricing, Windsor.ai also helps keep compute and storage costs under control. Orchestration is streamlined, too — you can set up pipelines and manage workflows with automated refreshes, all without needing a full data or DevOps team.
For businesses without large in-house data engineering teams, tools like Windsor.ai make it easy to automate and scale ELT pipelines, reduce technical overhead, and focus on what matters most: streaming raw data into any destination within minutes — no coding required.
Why use Windsor.ai ELT
✅ Connect to 325+ data sources
Windsor.ai makes data syncing easier than ever. You can aggregate data from over 325 data sources, including ad platforms, SEO tools, social media networks, analytics tools, CRMs, databases, and business apps.
✅ Fast, no-code ELT pipelines
No need to write a single line of code. Just connect your data source and account, choose the fields you’d like to pull, select the destination, and start the integration process. After that, you clean and tweak the data right in your warehouse with SQL or Python. It keeps everything smooth and low-maintenance.
✅ Real-time sync and automation
You can set up schedules for updating your data in the connected destination. So there’s no more dragging files around or messing with spreadsheets. Keep your dashboards up to date without lifting a finger.
✅ Reliable monitoring and support
With Windsor.ai, you can easily monitor your ELT data pipelines—including job status and error tracking—directly from the dashboard. If any issues arise, our customer support team is ready to provide quick assistance and help you resolve them promptly.
✅ One platform for data teams and marketers
Windsor.ai unifies your data across sources and teams, breaking down silos, so everyone—from data engineers to marketers—can access consistent, reliable information in one place. This streamlined ELT setup simplifies reporting and collaboration, making it easy to deliver insights to both internal teams and clients.
✅ Affordable pricing
Compared to many expensive ELT tools such as Fivetran, Supermetrics, and Stitch, Windsor.ai offers transparent, cost-effective pricing plans starting at just $19/month. Every plan includes access to all data sources and destinations—no premium connectors or hidden fees. Plus, you can try Windsor.ai risk-free with a 30-day free trial before committing.
How to build an ELT data pipeline
You can build ELT data pipelines manually, but it often requires significant time, extensive technical skills, and ongoing maintenance. This involves writing custom code or scripts to extract data from sources, load it into your destination via CSV files or other methods, and transform it using SQL or programming languages. You’d also need to manage scheduling, error handling, and monitoring yourself, which usually requires knowledge of Python.
However, automated ELT tools like Windsor.ai simplify and fully automate this process by handling all ELT steps out of the box. We provide connectors to numerous data sources, automate data extraction and loading, offer built-in transformation capabilities, scheduling, monitoring, and alerts—all without requiring you to build and maintain complex custom infrastructure.
Here’s how you can create an ELT data pipeline with Windsor.ai in under 5 minutes:
1. Create an account and log in.
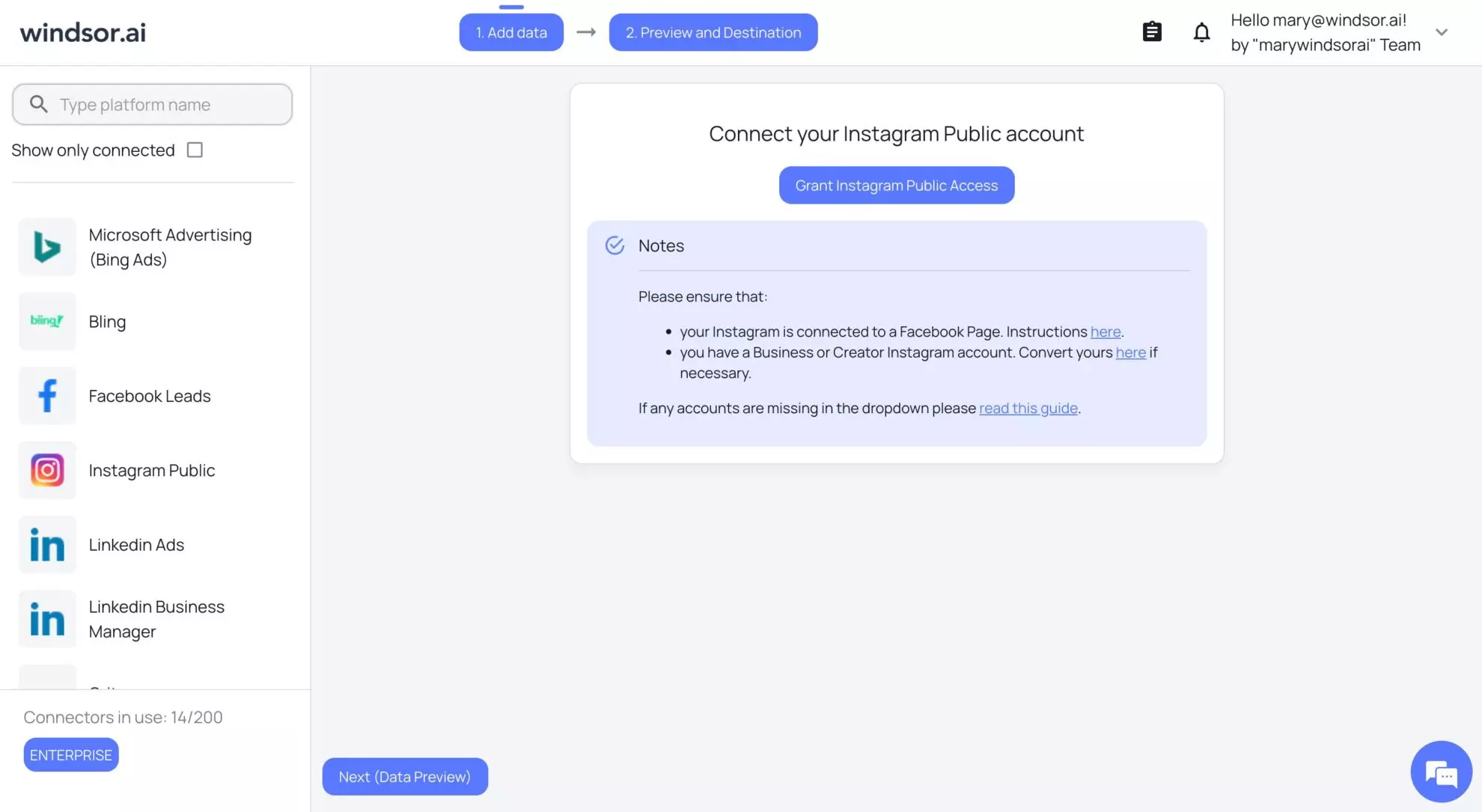
2. Connect your data source and select the account(s) from which you want to pull data:
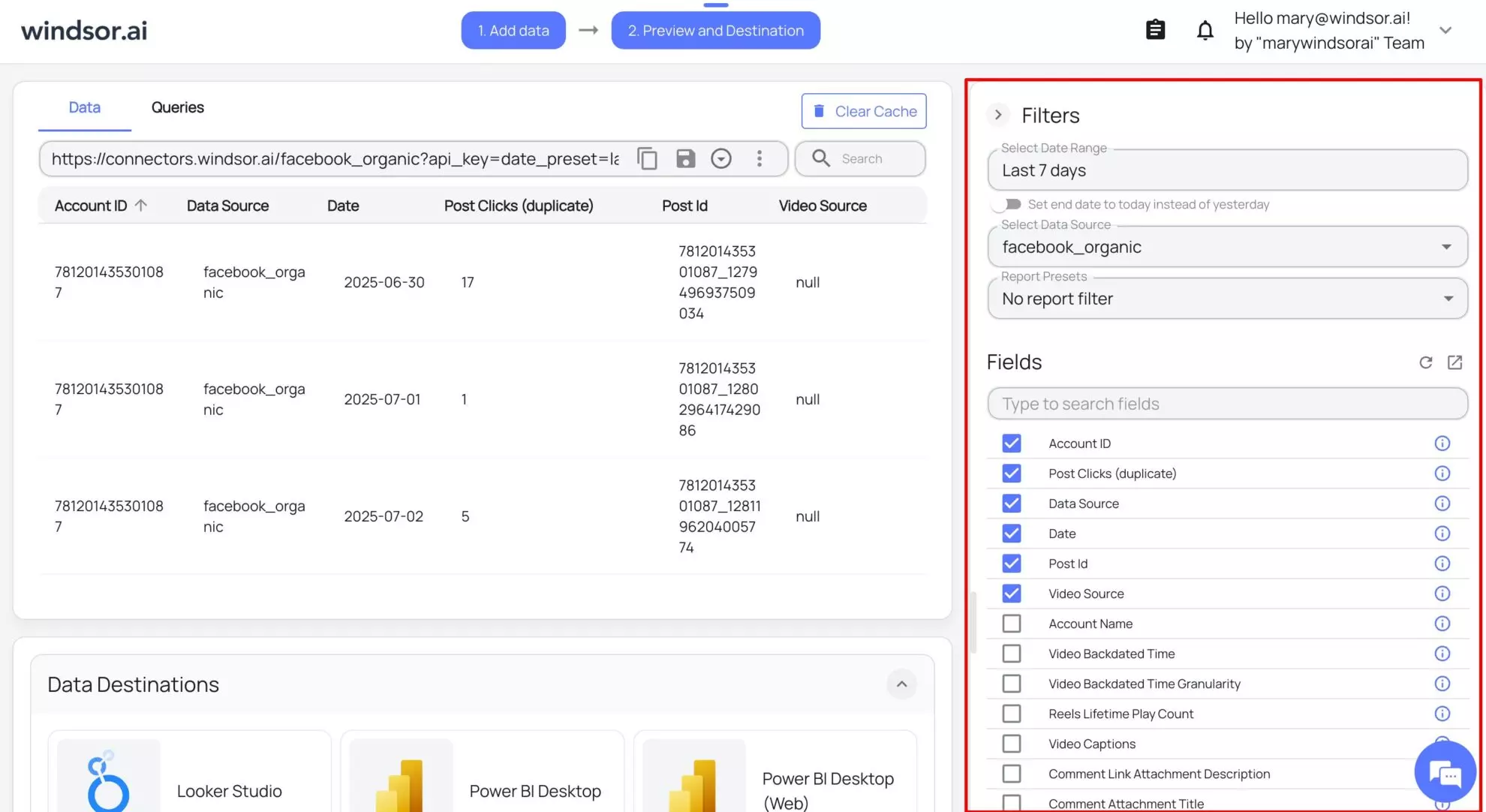
3. Click Next and select the date range and fields given in the right panel to fetch the desired data. Preview your data in the table:
4. Scroll down and choose your data destination:
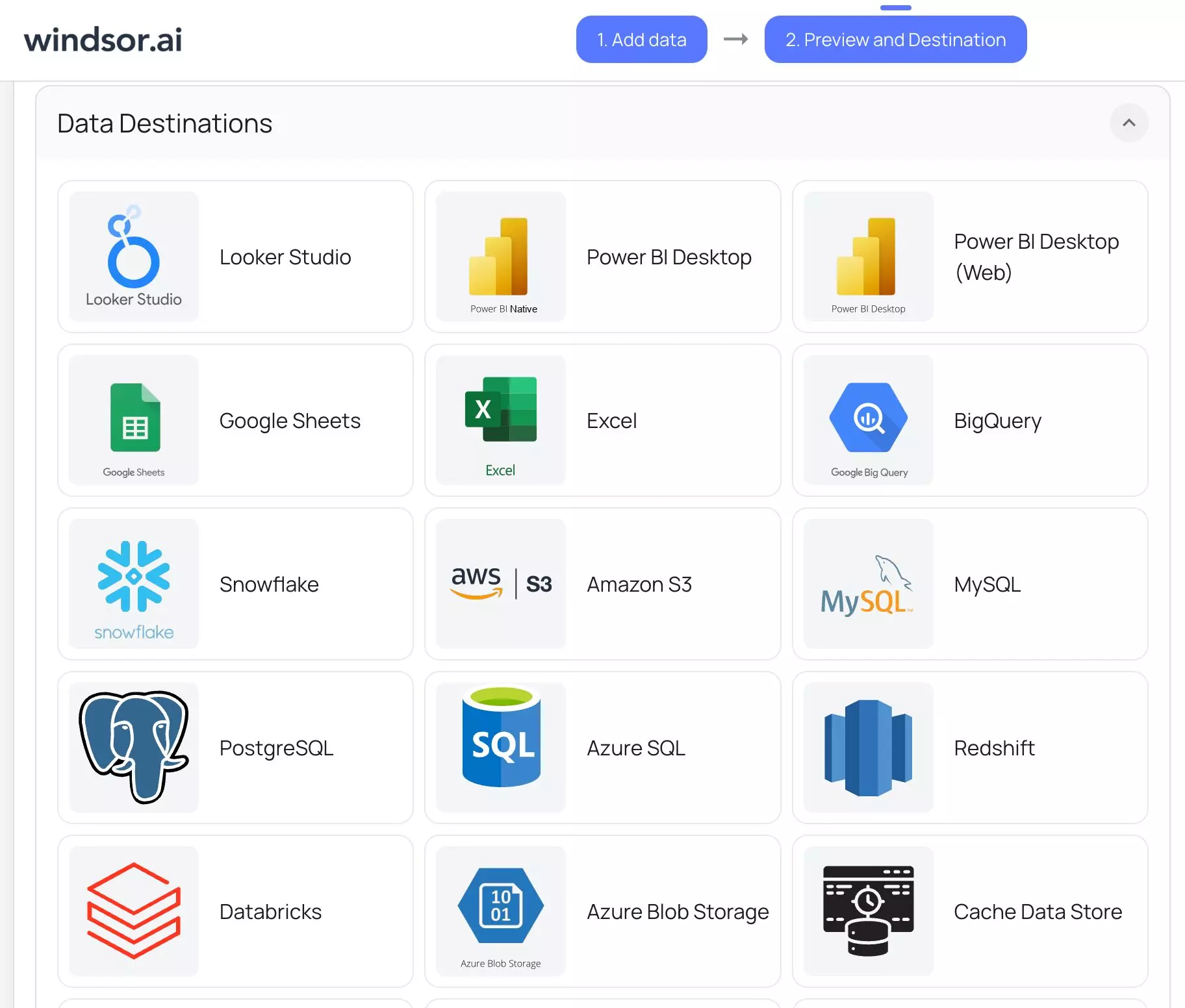
5. Connect your data destination by following the instructions given on the screen.
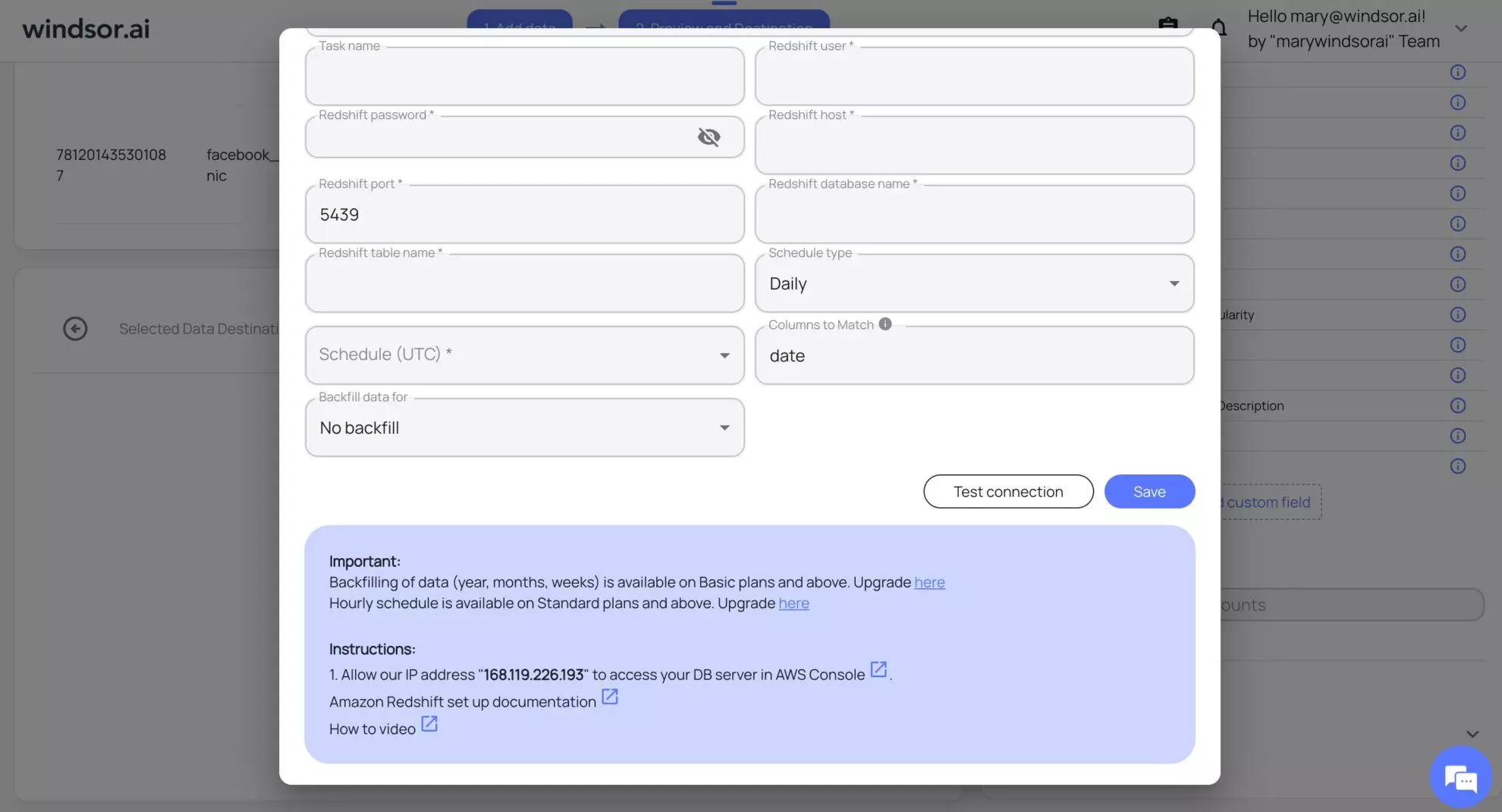
Congrats! You successfully created your first ELT data pipeline with Windsor.ai in just 5 minutes.
Conclusion
ELT data pipelines are essential for modern businesses, especially for marketing and data teams, to manage and make sense of the massive volumes of data generated daily.
By extracting raw data, loading it directly into powerful cloud warehouses, and transforming it there, ELT enables faster, more flexible, and scalable data workflows. While building ELT pipelines manually is possible, automated ELT tools like Windsor.ai simplify the entire process, saving you time, reducing errors, and letting your teams focus on insights instead of data plumbing.
Ready to streamline your data integration and unlock the full potential of your data? Try Windsor.ai today with a free 30-day trial and experience effortless ELT pipelines in minutes.
Start your free trial at Windsor.ai.
FAQs
What is an ELT data pipeline?
ELT stands for Extract, Load, and Transform — it’s a modern approach to moving data from source systems like apps or databases into analytics or storage environments such as cloud data warehouses, data lakes, or BI platforms for further processing.
Why do you need ELT pipelines?
ELT pipelines are ideal if you need to extract and preview massive datasets quickly, then handle cleanup and structuring later.
Can ELT pipelines handle real-time data processing?
ELT works best with batch processing. While near real-time is possible, it’s more complex and often more expensive. If you need live updates, consider using third-party ELT tools that support near real-time sync.
How does ELT work with cloud data warehouses?
Raw data gets loaded first. After that, you perform necessary transformations right inside the data warehouse using SQL or Python, leveraging the native platform’s capabilities.
Is ELT suitable for small businesses or only large enterprises?
Businesses of all sizes can benefit from ELT. No worries if you don’t have an in-house data team; with Windsor.ai’s no-code ELT connectors, you can set up complex ELT pipelines and manage workflows with automated refreshes, all without needing data engineers on board.
What is the difference between batch processing and ELT pipelines?
Batch runs at fixed times. ELT does that too, but can also load fresh data. Windsor.ai handles both batch processing and ELT pipelines.
How much does it cost to implement an ELT pipeline?
The manual method is free to use and involves only destination fees. In case you decide to use automated ELT tools, the pricing varies significantly.
Compared to many expensive ELT tools, like Fivetran, Supermetrics, Stitch, etc., Windsor.ai offers transparent, cost-effective pricing plans starting at just $19/month.
Every plan includes access to all data sources and destinations—no premium connectors or hidden fees. Plus, you can try Windsor.ai risk-free with a 30-day free trial before committing.

