 AI insights
AI insights About us
About us Careers
Careers Security
Security Customer reviews
Customer reviews Contact us
Contact us Affiliate program
Affiliate program Solution partners
Solution partners Looker Studio templates
Looker Studio templates Tableau templates
Tableau templates Facebook Ads templates
Facebook Ads templates Google Ads templates
Google Ads templates Data fields & Metrics
Data fields & Metrics AI prompt library & Guides
AI prompt library & Guides Product documentation
Product documentation API documentation
API documentation Case studies
Case studies Blog
Blog Data models
Data models Windsor vs Supermetrics
Windsor vs Supermetrics Windsor vs Fivetran
Windsor vs Fivetran Windsor vs Portermetrics
Windsor vs Portermetrics Last updated: 29 July 2025
Last updated: 29 July 2025

Data is everywhere, and yet many still struggle to use it effectively. At the same time, 73% of business leaders believe that integrated data reduces uncertainty and leads to better decisions.
But here’s the catch: getting your data in one place, clean and usable, is often where things fall apart. That’s where ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) come in — two powerful approaches to building data pipelines.
What are the main differences between ETL and ELT? Both sound similar. However, not understanding their specifics and choosing the wrong one can slow you down, increase costs, or limit the insights you gain.
Here’s the quick distinction:
- ETL: Extract → Transform → Load (transform before loading to the warehouse)
- ELT: Extract → Load → Transform (load first, transform inside the warehouse)
So, it’s about the same job but in a different order.
But still, which one should you use?
Read on to get a clear breakdown of both methods — their key differences, pros and cons, and use cases. And if you want to eliminate messy pipelines or endless custom scripts, I’ll also show how you can automate the entire process using Windsor.ai — a no-code data integration platform that connects 325+ data sources and makes ETL/ELT simple.
Let’s move forward.
What is ETL?
ETL stands for Extract, Transform, Load. It’s the process of aggregating and moving data from different tools into one place. Usually, a data warehouse. The ETL approach has been around for a long time and still powers many traditional reporting systems.
Here’s how it usually works:
- First, you grab the data from wherever it’s sitting—in your CRM, SaaS app, database, spreadsheet, or pulled in through an API.
- Then, you clean it up, ensure it’s in the correct format, and apply any rules your team follows.
- Once that’s done, you stream this clean data into your reporting, storage, or analytics system for further processing.

This setup is widespread in on-premise environments. Before cloud storage became the norm, you had to make sure the data was clean before storing it. Storage was expensive, and streaming messy data just wasn’t an option.
That’s why the “transform” step comes before “load” in ETL. The data had to be structured and accurate before landing in your destination.
ETL works best when your data needs serious preparation. At the Transform stage, you can clean the duplicate values, fix any format-related issues, or standardize data gathered across different platforms.
It’s most helpful where high data accuracy matters, such as in finance or healthcare sectors.
Also, notable to note that ETL jobs typically run in batches, either daily or hourly, rather than in real-time.
While modern systems tend to lean toward near-real-time ELT data pipelines, ETL still plays a crucial role in the data management world. It’s stable, battle-tested, and often the better choice when data accuracy is critical and there’s no margin for error.
What is ELT?
ELT follows these steps: Extract, Load, Transform. It’s a modern approach to handling data at scale, especially in cloud-first environments. Think of it as the faster, more scalable sibling of the traditional ETL process.
Here’s how it works:
- First, you extract raw data from different sources, CRMs, ad platforms, databases, APIs, etc.
- Then, you load that data directly into your preferred destination; most often, to a cloud data warehouse, such as BigQuery or Snowflake.
-
Only after loading do you transform the data using SQL or other tools within the destination.
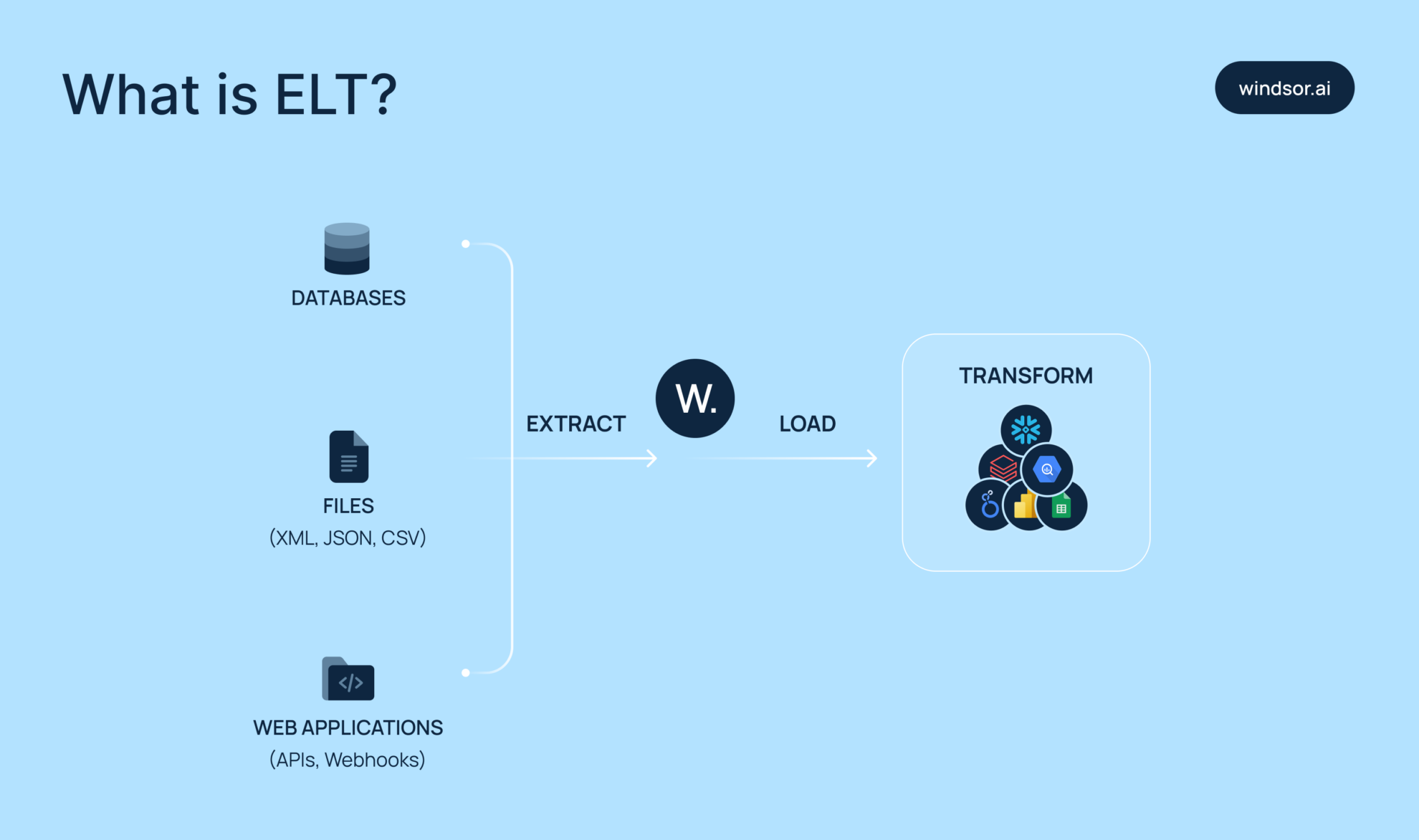
This is different from the old ETL model, where data was transformed before loading. With ELT, the raw data remains intact, providing you with more flexibility to reprocess or revisit it later. You can also skip the bottlenecks of early transformations.
Cloud data warehouses are specifically designed for ELT purposes. They’re optimized for large-scale storage and fast, distributed computing. That means you can run heavy SQL transformations right where the data lands, without copying or moving it again.
The ELT setup also works nicely for teams. Analysts and engineers can collaborate on live data models using SQL-based tools. No need to rely on rigid pipelines or wait for developer support.
That’s how ELT gives you speed, flexibility, and control over your data. It’s ideal for modern data stacks, especially when your data lives across many sources and updates too frequently.
So, if you’re working with Snowflake, BigQuery, Databricks, or Redshift, ELT, in most cases, is the most suitable approach.
ETL vs ELT: Comparison table
| Feature | ETL | ELT |
| Transformation step | Before loading data into the destination (in a staging area) | After loading data into the destination (inside the data warehouse or lake) |
| Order of operations | Extract → Transform → Load | Extract → Load → Transform |
| Speed | Slower overall due to transformation before loading | Faster loading; transformation happens after loading |
| Latency | Higher latency due to pre-load processing | Lower latency—data becomes available immediately after loading |
| Scalability | Limited by infrastructure and processing capacity | Highly scalable with cloud-based platforms |
| Flexibility | Less flexible; fixed schema required before loading | More flexible; supports unstructured, semi-structured, and raw data |
| Maintenance | Requires more ongoing development and monitoring | Minimal effort; many tools are no-code/low-code and cloud-managed |
| Cost efficiency | More predictable costs if transformation happens outside the warehouse | Potentially higher costs due to cloud transformation compute usage |
| Compliance | Easier to enforce data privacy and security before data enters the warehouse | Riskier; sensitive data is stored before cleansing and may violate compliance |
| Data quality | Strong control—bad data is stopped at the staging level | Risk of low-quality/raw data accumulation (“data swamp”) |
| Transformation complexity | Supports complex transformations before storage | May require powerful processing engines for complex in-warehouse transformations |
| Storage requirements | Lower storage needs; only clean data is stored | Higher storage usage; raw data is stored before transformation |
| Use cases | Financial reporting, legacy system integration, batch jobs | Real-time analytics, big data environments, machine learning training |
| Best for | Structured data, compliance-heavy environments | Cloud-native apps, high-volume, real-time streaming scenarios |
| Technology compatibility | On-premises, relational databases, traditional warehouses | Cloud data lakes and warehouses |
| Analytical flexibility | Limited; raw data discarded after transformation | High; raw data available for multiple transformation paths |
| Data engineers availability | Easier to find ETL experts due to the maturity of the field | Harder to find ELT specialists; skillset still emerging |
| Tooling ecosystem | Mature, wide range of tools and vendors | Rapidly evolving, fewer tools but robust cloud-native offerings |
| Real-time streaming capability | Traditionally batch-focused; newer ETL tools support near real-time | Designed with real-time and near-real-time capabilities |
ETL vs ELT: Use cases
ETL use cases
ETL plays a vital role in data workflows that aren’t built for the cloud, thus, aren’t designed to handle raw data dumps.
Here are some real-world examples:
- Suppose you use legacy data warehouses with strict schema rules. In such cases, you need to rely on the ETL approach to clean and shape the data before loading it into the destination.
- In industries such as finance or healthcare, compliance is a serious topic. Sensitive data often needs to be anonymized or filtered before storage. ETL enables teams to apply these rules early, reducing downstream risk and making audits easier.
- Not all transformation logic is light. Sometimes it involves nested rules, joins, or lookups that require precise control. ETL pipelines enable versioning, validation, and strict governance before data enters the warehouse. That’s especially useful when consistency and accuracy are critical.
ELT is fast and cloud-native, but assumes your storage can handle raw, messy data. ETL takes a more cautious route, ideal for teams working with rigid systems or heavy regulations. It may not be as trendy, but in the right context, it’s still the effective solution.
If your architecture is rigid, your compliance needs are strict, or your transformation logic is complex, ETL is a proven choice.
ELT use cases
ELT is a critical process for any business working with fast-moving, high-volume data. And it’s reshaping how teams handle analytics:
- Most teams today pull data from dozens of sources, such as Google Ads, Shopify, Salesforce, etc.. ELT enables you to bring it all together in one place, most often, a centralized data warehouse. That unified view makes analysis faster and far more reliable and comprehensive.
- Need live insights? ELT pipelines can stream data continuously into dashboards. You get up-to-date metrics with advanced breakdowns, eliminating the need for generating daily reports.
- Product teams want to track every click, scroll, and purchase. ELT handles this scope effortlessly. By streaming raw event data into your analytics environment, you can uncover user patterns, segment audiences, and run behavioral cohort analysis with ease.
- Startups love ELT for its speed and cost-effectiveness. Enterprises trust it for its scalability and automated integration with modern data warehouses. Cloud-native platforms — with cheap storage and elastic compute — make ELT the go-to approach for teams managing ever-changing data volumes.
In short, ELT helps turn messy, scattered data into clean, usable insights, whether you’re crafting client reports, optimizing campaigns, or improving app flows.
It’s the backbone of modern analytics. No manual stitching. Just immediate access to always fresh, accurate cross-channel data you can trust.
Pros and cons of ETL and ELT
ETL pros
Despite the rise of ELT, ETL remains a trusted approach, and for good reasons:
- You control the input. ETL works best when your data sources are well-defined and consistent.
- Pre-cleaned, pre-structured data. You can clean, validate, and transform everything before it reaches your warehouse, minimizing clutter and ensuring quality.
- Familiarity breeds trust. Many enterprise teams stick with ETL because it’s reliable, well-understood, and fits into existing data governance frameworks.
ETL cons
While ETL still has its place, it can struggle under modern data demands:
- Big, messy data? ETL slows down. When datasets grow or become inconsistent, ETL pipelines get fragile and inefficient.
- Schema changes = pipeline breaks. ETL is rigid; even a small change in the source’s API can cause failure.
- Limited compatibility with modern cloud tools. ETL doesn’t always play nicely with cloud-native platforms or tools.
- Semi-structured data? Not ideal. JSON, nested formats, or NoSQL exports often don’t fit well in traditional ETL flows.
- Built for batch, not real-time. ETL was designed for periodic loads, not for today’s streaming or event-driven systems.
Verdict: ETL still works well for stable, controlled environments, especially when accuracy and pre-validation matter most.
But if you’re working with fast-changing, large-scale, or cloud-native data, it might be time to move on.
ETL isn’t dead, but it’s not one-size-fits-all anymore. You have to know your data needs and pick what works now, not what worked five years ago.
ELT pros
If you need to sync data from a few different tools, ELT is a real lifesaver thanks to these features:
- Handles messy marketing data with ease. ELT lets you pull raw data from CRMs, ad platforms, web analytics, and more — all into a single source of truth.
- Works seamlessly with modern BI tools. Platforms like Looker Studio and Power BI are built to query raw data directly, making ELT a natural fit.
- Flexible and scalable architecture. ELT doesn’t force rigid workflows; you can transform data after loading it, adapting as your needs evolve.
- Ready for real-time and API-driven data. ELT excels at handling high-volume, frequently changing inputs from APIs like Meta Ads, Google Ads, HubSpot, Typeform, etc..
ELT cons
ELT is the go-to approach for modern data teams — but it’s not without trade-offs:
- Warehouse performance matters. Without a fast, scalable data warehouse, ELT pipelines can slow down dramatically.
- Cost can spiral fast. Poorly optimized SQL queries or frequent large-scale transformations can lead to unexpected compute charges.
- Without automation, complexity creeps in. Managing ELT manually — or with the wrong tool — can quickly become messy, time-consuming, and expensive.
- Post-load transformations delay insights. There’s often a lag before the data is clean and analysis-ready, especially without automation or scheduled jobs.
- Requires strong data governance. There’s more room for inconsistent definitions, duplicated logic, and versioning issues if governance and naming conventions aren’t enforced.
Verdict: ELT perfectly aligns with the way modern data teams operate. To make the most out of it and eliminate the abovementioned cons, you should utilize a high-performance data warehouse, write well-structured, efficient SQL queries, and use a reliable, cost-effective ELT platform that automates integration, transformation, and data quality.
ETL vs. ELT? With Windsor.ai, you don’t have to choose
Choosing between ETL and ELT can be tough. You want clean, structured data. But you also need your pipelines to be flexible, fast, and scalable. That’s where Windsor.ai comes in.

Windsor combines full ELT functionality with optional pre-load transformations. You decide when and where to clean your data — before or after it hits your warehouse.
✅ Need clean data before storing it?
Use Windsor’s ETL flow to extract, transform, and then load it into your warehouse.
✅ Want to move fast and clean data later?
Load raw data first. Then use Windsor’s ELT features to transform it directly in your storage layer.
With this hybrid approach, you get the best of both worlds:
- High data quality where it matters.
- Speed and flexibility when time is critical.
- Simpler, scalable pipelines — no dev support is required.
Windsor.ai is built for marketers and data engineering teams who want clean, usable data without writing a single line of code or custom scripts. It allows you to pull data from platforms like Google Ads, Facebook, Shopify, and 300+ more.
Then Windsor.ai streams it straight to your BI tool or cloud warehouse. Looker Studio, Power BI, BigQuery, Snowflake, Redshift, or others — it integrates smoothly with the most popular destinations.
The best part of using Windsor.ai is that it eliminates all technical complexities and delivers pipeline setup in minutes. You just connect your data sources, select the reporting fields, apply basic transformations if needed, pick your destination, and schedule automatic syncs. That’s it.
Once it’s flowing, your data auto-refreshes at your preferred schedule. Always fresh and ready for whatever reporting or analytical tools you use.
Windsor.ai is ideal for teams who are tired of manual data wrangling and spending engineering time on routine work. Whether you need to combine data from multiple platforms or automate reporting, Windsor lets you move fast.
Key features of Windsor.ai
✅ 325+ connectors
You can aggregate data from the most popular platforms, including Meta, Google Ads, Shopify, LinkedIn, and hundreds more. No need for custom API work or CSV exports. Simply connect a data source, select the account(s), and let the platform handle data integration.

All your data flows into one centralized, clean, and fully normalized schema, saving hours of manual work each week. Especially valuable for teams juggling multiple platforms or fragmented tools.
✅ Real-time sync
Your data stays fresh — always. Windsor pushes it to your connected destination in near real-time at the set schedule, so you can rely on the latest numbers when reporting, debugging campaigns, or performing other operations.

It’s a big step up from batch exports or manual updates.
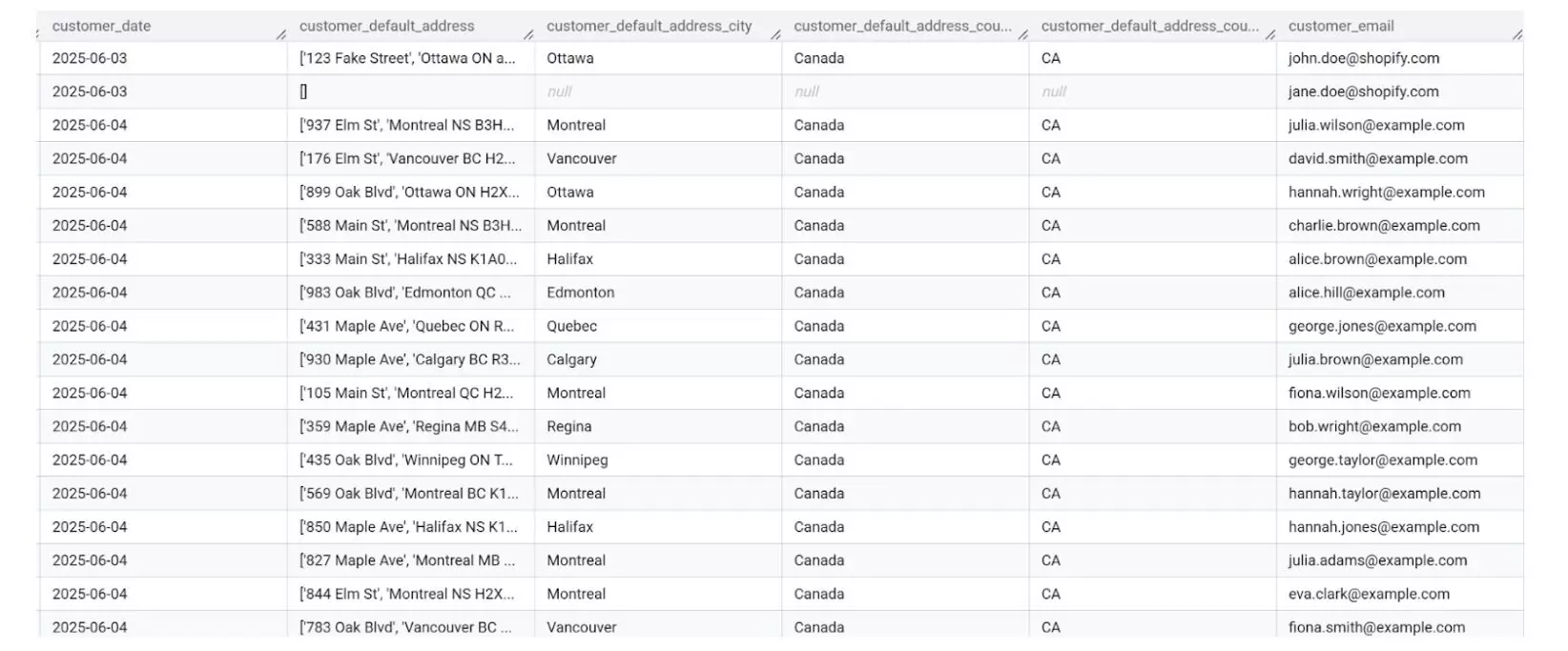
✅ Schema-aware sync – prevents data duplication or errors
Windsor.ai checks your schema before syncing. That means no duplicate rows, no weird values, no broken dashboards.
If a source API changes, Windsor handles it without blowing things up. You get clean, accurate data without having to fix stuff after the loading, saving you from many silent errors.
✅ No-code setup
With Windsor.ai, anyone on your team can build powerful ELT pipelines — no developers, no custom scripts, no technical hurdles.
Just choose your data sources and destinations, click through a few guided steps, and your pipeline is ready to run.
It’s ideal for marketers or analysts who need instant access to holistic data.
✅ Flat pricing from $19/month – all connectors & destinations included
You get access to all connectors and destinations — no surprise fees or extra charges for some niche sources. Every plan includes full platform access, so you can integrate data from anywhere to anywhere without upsells.

And the best part? Windsor lets you stream data into modern warehouses like BigQuery or Snowflake starting at just $19/month, while many competitors charge $500+ for the same capability.
✅ No maintenance required – automatic schema evolution
Data landscape changes constantly — new columns, new campaign types, new field names. Windsor.ai handles it all automatically. It detects schema changes in your source APIs and automatically adapts your pipelines, without breaking or requiring manual intervention.
No more rebuilding workflows or pulling in developers when a platform updates its structure. It’s built to be maintenance-free, so you can stay focused on insights, not setups.
Real-world example from Windsor.ai: Omnicom Media Group HK success story
Omnicom Media Group Hong Kong replaced fragile ETL scripts with Windsor.ai’s automated ELT pipelines to unify data from 11 media platforms across 1,900 ad accounts — all directly into BigQuery with sub-2-hour latency.
Key results:
✅ 40+ hours/week saved, eliminating manual CSV exports and script maintenance.
✅ Real-time dashboards powered by automatic BigQuery syncs.
✅ Automatic schema evolution — no breaks when APIs change
✅ 100% naming taxonomy adoption across all media teams in 8 weeks.
Windsor’s hybrid architecture now powers all of Omnicom’s omnichannel reporting, with no engineering, no firefighting, and brings in massive time savings.
Read the entire case study here: https://windsor.ai/case-studies/omnicom-media-group-hong-kong/.
Conclusion
Eventually, ETL vs ELT – who wins the battle?
ETL transforms your data before loading it into the database. It’s a solid option for legacy systems or when your structure needs to be fixed upfront. But it can slow things down and isn’t built for scale.
ELT flips that. It loads everything first, then transforms inside your destination. That means faster data processing, better scalability, and real-time updates. It works way better with modern data stacks.
So:
✅ Go ELT if your team needs speed, agility, and centralized reporting across many sources.
✅ Stick with ETL if your business demands strict data control, compliance, or operates in a highly regulated environment.
Or… Why not leverage the benefits of both?
Windsor.ai gives you the best of both worlds — ETL and ELT in one no-code platform:
- Sync data from 325+ platforms (Google Ads, Meta, Shopify, etc.)
- Apply optional pre-load transformations right in the dashboard
- Stream data to BigQuery, Snowflake, Redshift, Looker Studio, and more
- No scripts. No engineering. Just clean, centralized data in minutes
If you’re tired of building pipelines from scratch or managing fragile scripts, it’s time to try Windsor.ai.
Start your free trial with Windsor.ai today and build complex ELT/ETL pipelines in minutes!
FAQs
What is the main difference between ETL and ELT?
In ETL, you clean your data before it’s stored. In ELT, you dump data first, then do the cleanup inside your data warehouse.
Is ELT better than ETL?
If you’re in analytics, ELT just makes more sense. You receive the raw data faster, allowing you to dive in, test, and act more quickly. Also, most modern tools are built to work this way.
Does Windsor.ai support both ETL and ELT?
Yes. Windsor lets you pull, load, and transform your data in a different order. Whether you want basic ETL or full ELT pipelines, it’s built to handle both.
Do I need coding skills to use Windsor.ai?
No. You just need to connect your data sources, select the reporting fields, pick the destination, and it just works.
Is ELT the future of ETL?
Absolutely — and it’s already happening. Cloud data warehouses have shifted the game, making ELT the default for teams that need speed, scalability, and flexibility. Most modern data stacks are built around ELT today, and this trend is only accelerating.
Will ELT replace ETL?
Not entirely. ETL still has its place, especially when you’re dealing with sensitive data, strict compliance requirements, or need to clean and validate data before storage.
But for most cloud-native setups, ELT is becoming the preferred choice. It’s faster, more scalable, and simplifies data operations, making it a better fit for modern teams and real-time analytics.
ELT or ETL: Which pipeline type is right for my business?
Depends on your setup. If you’re in the cloud and want things to be fast and flexible, ELT is your go-to solution. However, if your data requires serious cleanup before it’s processed, old-school ETL still has its place.

